One of the early stages of the Machine Learning projects pipelines is called Feature Engineering. And one of the actions we perform in that stage is creating new features based on the available dataset.
ML.NET has a long list of Transforms to support different operations, but sometimes you want to do something special. In my Portimão blog post I wanted to calculate a new feature by multiplying two existing features.
What I had in mind was not supported. Fortunately you can also use Custom Mapping and provide it a function that will perform the transformation. Below example how you can add it to your calculation pipeline.
This also require some small changes in your Data object, but in general is an elegant way to solve that issue. Microsoft has some more examples for CustomMapping transform.
Disclaimer: The F1 FORMULA 1 logo, F1 logo, FORMULA 1, F1, FIA FORMULA ONE WORLD CHAMPIONSHIP, GRAND PRIX and related marks are trademarks of Formula One Licensing BV, a Formula 1 company. All rights reserved. I’m just a dude in a basement with too much time on my hands.
This post is the fourth part of my approach to use ML.NET to make some predictions for strategies that teams will approach in Formula1. I highly suggest reading the first part, where I explain the approach I took.
Monaco Grand Prix is all about tradition and prestige.
The first race on the streets of Monaco took place in 1929, although not as a part of Formula 1. The track changes a bit over time, but in general stayed the same, as the street layout didn’t change. It is narrow with tight corners and nearly no run-off areas. There’s no room for error. It is the most prestigious race, and even though there are no extra points for winning it, it has a special place in many drivers hearts. The racing is not fascinating as overtaking is hard and usually order doesn’t change much from qualification, unless some accidents happen (which is quite possible on the tight circuit). The real charm is not in racing in Monaco but in the spectacular views, accompanying events and overall glamour of the race weekend.
In terms of tyres, the streets are resurfaced every year and the surface is not very abrasive compared to other races. Traditionally the three softest tyres are used for the grand prix, so the hardest tyre here (C3) is the same as the softest one in Spain. And it’s nearly never used as it’s simply not grippy enough.
Tyre choices for Spanish Grand Prix…versus choices for Monaco Grand Prix. Source: F1TV.com
Changes in dataset
For reasons mentioned below, I decided to add the “Distance” column (by calculating Track Length times number of laps) to the dataset physically. I also added data on all new races in 2021 since previous post (Spanish Grand Prix) and data from Monaco Grand Prix from 2017-2019 period (2020 was initially postponed and eventually cancelled). This give us around 200 new rows and brings the total up to around 950.
Changes in code
I continued on top of the previous post experiment with AutoML. The problem I had is I couldn’t pass a pipeline to the AutoML to make use of the additional information I have about the dataset to make training easier. But I found a way to pass information about which columns are categories and which are numerical using the ColumnInformation object:
I also experimented with using PreFeaturizer to pass information about converting the Laps feature into covered Distance feature (check out part 2 for details on that). This didn’t work out so well. It seems that it works OK for features that are not used as labels, but in this case looks like the model gets confused as it’s fitting for a feature that’s not in the input dataset. For more information on using custom transformers with AutoML checkout information in this repository.
So instead I decided to add that calculated feature (Distance = TrackLength * Laps) directly into the dataset and use it as our training label. So I dropped the PreFeaturizer, but kept the ColumnInformation as it looks like it increased the performance of the model.
Let’s look at those metrics after those changes:
=============== Training the model =============== Running AutoML regression experiment for 600 seconds... Top models ranked by R-Squared -- | Trainer RSquared Absolute-loss Squared-loss RMS-loss Duration | |1 FastTreeTweedieRegression 0,4342 26005,21 1059975156,71 32557,26 0,9 | |2 FastTreeTweedieRegression 0,4337 26270,96 1061084915,03 32574,30 0,6 | |3 FastTreeTweedieRegression 0,4245 26281,03 1078213169,63 32836,16 0,8 | ===== Evaluating model's accuracy with test data ===== ************************************************* * Metrics for FastTreeTweedieRegression regression model *------------------------------------------------ * LossFn: 1059975153,93 * R2 Score: 0,43 * Absolute loss: 26005,21 * Squared loss: 1059975156,71 * RMS loss: 32557,26 *************************************************
0,43 on the R-squared is another step up from 0,31 from last week and negative in the first two weeks. I’m happy with that progress!
The version of the code used in this post can be found here.
Predictions for Spanish Grand Prix
So here are the predictions for the first stint on the soft tyres for the top 10 on the starting grid. I’ll update actual values after the race.
Driver
Compound
Prediction
Actual
Charles Leclerc
C5
21,3
0 (DNS)
Max Verstappen
C5
22,0
35
Valtteri Bottas
C5
22,1
29
Carlos Sainz
C5
21,3
33
Lando Norris
C5
19,4
31
Pierre Gasly
C5
22,8
32
Lewis Hamilton
C5
22,2
31
Sebastian Vettel
C5
14,9
33
Sergio Pérez
C5
22,0
36
Antonio Giovinazzi
C5
23,8
35
Esteban Ocon
C5
27,3
37
They seem pretty consistent with prediction from the official Formula 1 website (they predict 19-26 laps for the first stint). Let’s see how it will match the reality.
Updated: Updated the prediction using the actual temperatures at the beginning of the race instead of forecast. Added actual values. The results are a bit away. Monaco is a tricky and unpredictable track and looks like this year’s resurface is much less violent to the tyres. Let’s count it as a failure :)
What’s next
Although we’ve made some progress, I think I’m reaching the limit of the current model. In the next part I’ll reorganize the code a bit. Split the training and inference and add some visualization. All to that to support future support for multiple models and easier visualization of how they differ in performance. My goal is to be able to make automated graphics similar to what you can find in post like this and this.
Disclaimer: The F1 FORMULA 1 logo, F1 logo, FORMULA 1, F1, FIA FORMULA ONE WORLD CHAMPIONSHIP, GRAND PRIX and related marks are trademarks of Formula One Licensing BV, a Formula 1 company. All rights reserved. I’m just a dude in a basement with too much time on my hands.
This post is the third part of my approach to use ML.NET to make some predictions for strategies that teams will approach in Formula1. I highly suggest reading the first part, where I explain the approach I took.
Spanish Grand Prix is probably the most predictible one
Usually at the beginning of each season teams spend a few days at the Catalunya racetrack testing. This year was exception with Bahrain due to the Covid-19 restrictions. Just to give you an example – over the whole of his career, Kimi Räikkönen did 5983 laps in testing and only 843 while racing around this track. Nearly 90% of laps he’s done at this track where while testing. Teams have a lot of data on this track and know it very well. This makes racing here predictable and to be honest quite boring. But Boring is good for predictions.
Changes in the dataset
The overall data structure stayed the same. As previously, I added data on all new races in 2021 since previous post (Portimão and Imola) and data from Spanish Grand Prix from 2017-2020 period. This give us 250 new rows and brings the total up to around 750.
Changes in the code
In the previous part I used the default regression model for training, and it didn’t perform very well. So I decided to give the AutoML a try. AutoML dos what the name suggests – automatically looks for the best model. You declare how much time you want to spend on an experiment and let the ML.NET try out multiple algorithms with different parameters:
Then you can pick up the best model out of that experiment, and you can run predictions using it:
RunDetail<RegressionMetrics> best = experimentResult.BestRun; ITransformer trainedModel = best.Model; var predictionEngine = mlContext.Model.CreatePredictionEngine<TyreStint, TyreStintPrediction>(trainedModel); var lh = new TyreStint() { Track = "Bahrain International Circuit", TrackLength = 5412f, Team = "Mercedes", Car = "W12", Driver = "Lewis Hamilton", Compound = "C3", AirTemperature = 20.5f, TrackTemperature = 28.3f, Reason = "Pit Stop" }; var lhPred = predictionEngine.Predict(lh);
The downside is, I haven’t figured out yet how to actually feed all that feature transformations we did in previous posts into the AutoML flow. So we cannot mark manually which data columns are categories or add new features like we did with distance. And predicting number of laps on tracks with different lap length makes me feel the results may be not so reliable. But let’s roll with it, and see where that leads us.
And the metrics look quite promising. The best algorithm after 10 minute experiment ended up being Fast Tree Regression. And for the first time we have non-negative R-squared. That’s the best performing model on test data we had so far, even though we took a step back with the laps instead of distance.
=============== Training the model =============== Running AutoML regression experiment for 600 seconds... Top models ranked by R-Squared -- | Trainer RSquared Absolute-loss Squared-loss RMS-loss Duration | |1 FastTreeRegression 0,3971 5,49 52,55 7,21 2,2 | |2 FastTreeRegression 0,3880 5,53 53,86 7,28 3,6 | |3 FastTreeRegression 0,3731 5,50 54,11 7,32 18,0 | ===== Evaluating model's accuracy with test data ===== ************************************************* * Metrics for FastTreeRegression regression model *------------------------------------------------ * LossFn: 51,19 * R2 Score: 0,31 * Absolute loss: 5,29 * Squared loss: 51,19 * RMS loss: 7,15 *************************************************
Check out tha latest version of the code in the repository.
Predictions for Spanish Grand Prix
Without further ado, let’s do predictions for the Spanish Grand Prix. All the first 10 drivers will start on the soft tyres, which are C3 compound in Spain.
Tyre choices for 2021 Spanish Grand Prix. Source: F1TV.com
In the table below I put my predictions and the actual first stints (since it’s already after the GP). What’s very suspicious is that each of the teammates got the same scores, which makes me think that the model gave a lot of weight to the team, and not much to the driver. I was also surprised with those results being so high for soft tyres. But C3 is actually pretty hard compound for “soft tyre” (read the first post for more details on tyre compounds) and they ended up being quite reasonable. Similarly to the previous post, I bolded out the results that ended up within 10% of the actual value. Half of them were pretty close, which is consistent with metrics suggesting this is our best model yet.
Driver
Compound
Prediction
Actual
Max Verstappen
C3
26,7
24
Valtteri Bottas
C3
26,9
23
Lewis Hamilton
C3
26,9
28
Carlos Sainz
C3
26,7
22
Sergio Pérez
C3
26,7
27
Lando Norris
C3
26,5
23
Charles Leclerc
C3
26,7
28
Daniel Ricciardo
C3
27,2
25
Esteban Ocon
C3
26,8
23
Fernando Alonso
C3
26,8
21
What’s next
For the next post that will be in conjunction with the Monaco Grand Prix, I’ll try to feed that feature information we engineered in the first two posts into the AutoML and see if that helps that model get even better. But generally I feel we’re getting to limits what’s possible with that approach. We have a lot of categorical data and not so much numeric data, which makes it a bit hard for regression. I have a few ideas for new models, and we’ll explore them in future parts.
Disclaimer: The F1 FORMULA 1 logo, F1 logo, FORMULA 1, F1, FIA FORMULA ONE WORLD CHAMPIONSHIP, GRAND PRIX and related marks are trademarks of Formula One Licensing BV, a Formula 1 company. All rights reserved. I’m just a dude in a basement with too much time on my hands.
This post is the second part of my approach to use ML.NET to make some useful predictions about strategies that teams will approach in Formula1. I highly suggest reading the first part, where I explain the approach I took.
And yes, this episode is also too late to make predictions for Imola and Portimão, but hopefully by Spanish Grand Prix will be all caught up.
We’re not gonna get great results here
If you read the previous part you’re aware that I didn’t get spectacular results in the first run. Unfortunately, we won’t improve much here, because we don’t have much data for those tracks. In the period I focus on (2017-2020) there was only one race on each of those tracks. Imola, although a legendary track and hallowed ground for Formula1, is quite outdated and fell out of grace in recent years. Portimão is a very new track, and Portugal GP promoters were unable to attract Formula 1. Last time we raced in Portugal it was in 1996 on a different track – Estoril. But 2020 was a weird year because of COVID-19, and due to travel restrictions F1 needed to find more tracks in Europe. And so we went to Imola and Portimão.
But there are opportunities!
So even though we don’t expect dramatic improvement adding new tracks gives some new view into the data. Previously, since we only used data from one track, I used the number of laps as our Label – a number we were predicting. Since now, we have one than more track with different lengths we have to find a new feature/label to use. That’s how Distance was added to the model – I calculate the TrackLength times Laps covered.
Changes in dataset
I haven’t added any new columns to the dataset and the feature describe above is calculated in code. But I added a lot of rows. My approach is that for each race I’ll be adding previous 2021 races, and all the races since 2017 on the current track. So by applying this rule, I’ve added Bahrain 2021 (previous race) and Imola and Portimão 2020 (previous races on the current track).
Changes in code
There are two major changes in the code since last iteration. With the 4 new races added, we nearly doubled our data row count (from 250ish to nearly 500). Now I can be a bit more selective which rows I take into calculation. In the first approach, we want to predict strategy in situations where everything goes well, since we cannot predict unpredictable (rain, accidents, mechanical failures).
Removing unnaturally shortened stints
That’s why I decided to filter out all the rows with stints that end with something else than “Pit Stop” (which is regular unforced change of tyres) or “Race Finish”.
This is the piece of code that does it:
// Load data var data = mlContext.Data.LoadFromTextFile<TyreStint>(DatasetsLocation, ';', true); // Filtering data var filtered = mlContext.Data.FilterByCustomPredicate(data, (TyreStint row) => !(row.Reason.Equals("Pit Stop") || row.Reason.Equals("Race Finish")) ); var debugCount = mlContext.Data.CreateEnumerable<TyreStint>(filtered, reuseRowObject: false).Count(); //396 // Divide dataset into training and testing data var split = mlContext.Data.TrainTestSplit(filtered, testFraction: 0.1); var trainingData = split.TrainSet; var testingData = split.TestSet;
I use FilterByCustomPredicate method from the mlContext.Data. It takes a function which returns true for the rows we want to remove from the data.
The function itself is this small iniline piece of code:
I inserted this in between loading the data from files, and splitting the data, because I want both test and training data to be consistent. This leaves us with 396 rows of data. Nice, that makes me happy.
Using distance instead of laps as a feature
The second change was connected to using Distance instead of Laps as our new Label. I had to create a new feature Distance, by multiplying two other features – Laps and Track Length. ML.NET has a long list of Transforms to support different operations, but what I had in mind was not supported. Fortunately you can also use Custom Mapping and provide it a function that will perform the transformation. I added at the beginning of our calculation pipeline.
I also needed to recalculate distance back to laps at the end. I do it by again dividing the prediction by the distance of the current track.
prediction.Distance / race.Track.Distance
While looking at the code you’ll also notice that I refactored it a bit. I moved some classes into separate files. I also isolated some data and magic strings. Just general clean up, so step by step we move from one-file script mess into serious working application.
Newest predictions
Just for the sake of showing progress of lack of, let’s look at some predictions. I’m not going to predict all tyres for all the drivers. Let’s just take the first 10 qualifiers from the both races and predict how long can they go on the tyres they’ve chosen to start on and compare it to what happened in reality.
Imola
The predictions for Imola ended up being pointless. On the morning of the race it rained and all the assigned tyres are cancelled in a situation like that. Teams have to start on either Intermediate or Wet compounds. In the track conditions on that day Wet tyres were a mistake. The track was dump, but there was no standing water. If you look at the table, you will notice that all drivers on Intermediates change tyres around lap 27/28. This is because teams wait for a perfect moment when the track is ready for dry tyres and usually first person blinking and changing to dries will trigger all the other teams to react.
Name
Compund
Predicted
Actual
Notes
Lewis Hamilton
C3
23,17
28
Intermediate
Sergio Pérez
C4
14,03
28
Intermediate
Max Verstappen
C3
24,23
27
Intermediate
Charles Leclerc
C4
11,96
28
Intermediate
Pierre Gasly
C4
16,54
14
Wet
Daniel Ricciardo
C4
13,98
27
Intermediate
Lando Norris
C4
15,77
28
Intermediate
Valtteri Bottas
C3
26,96
28
Intermediate
Esteban Ocon
C4
15,04
1
Wet
Lance Stroll
C4
13,67
27
Intermediate
Portimão
The Portuguese Grand Prix didn’t provide any weather surprises. We had a dry race and could finally test our model. On some rows predictions were quite good. I marked in bold those, where we landed within 10% difference. Sergio’s result is an obvious outlier – he was used by the team to slow down Mercedes drivers to give a better chance to his teammate Max Verstappen. But he was the right man for the job. Sergio’s tyre management is excellent, definitely one of the best in the paddock.
Name
Compund
Predicted
Actual
Notes
Valtteri Bottas
C3
38,47
36
Lewis Hamilton
C2
34,48
37
Max Verstappen
C2
35,60
35
Sergio Pérez
C2
32,40
51
Sergio is a know “tyre whisperer” ;)
Carlos Sainz
C3
29,58
21
Esteban Ocon
C3
24,94
22
Lando Norris
C3
25,71
22
Charles Leclerc
C2
30,22
25
Pierre Gasly
C3
26,53
24
Sebastian Vettel
C3
30,45
22
What’s next?
Next up on the calendar is the Spanish Grand Prix. It’s a well known track to Formula 1 teams. They spend a week there near every year for pre-season testing. Teams like this track for its predictable surface and weather conditions. They know every inch of it and have it perfectly modelled in simulators. All that data makes racing here pathetically boring. But boring is good for predictions, right?
We’ll also take a stab at our model and for the first time try to improve it on top of just adding more data.
Disclaimer: The F1 FORMULA 1 logo, F1 logo, FORMULA 1, F1, FIA FORMULA ONE WORLD CHAMPIONSHIP, GRAND PRIX and related marks are trademarks of Formula One Licensing BV, a Formula 1 company. All rights reserved. I’m just a dude in a basement with too much time on my hands.
Let’s take out the first issue out of the way – I know it’s way too late to make predictions about the Bahrain race. I’ve been sitting on this blog post for quite some time, so I’m way behind. There is one more about Imola and Portimão incoming and hopefully by the Spanish Grand Prix will be all caught up.
Why am I gonna focus on tyres? (for now)
For the start, I will focus on the tyre strategy. Since refuelling was banned in 2009, choice of tyres and when to stop to change them has been a crucial part of the race strategy. In modern Formula 1 there’s only one tyre supplier – Pirelli. There are 5 compounds for dry condition (C1 is the hardest, and C5 the softest) and two types of tyres for wet conditions – “Wet” for heavy standing water on the track and Intermediate for the track that’s drying. For each race Pirelli picks three dry compounds for the teams and assign them more human-readable names – Hard (marked with white stripes), Medium (marked with yellow stripes) and Soft (marked with red stripes). So for example for Bahrain this year C2 was marked Hard, C3 – Medium and C4 – Soft. C1 and C5 were not used during that race.
Tyre choices for 2021 Bahrain Grand Prix. Source: F1TV.com.
For different races, those options may be different (for example in Portimão last week C1 was Hard, C2 – Medium, C3 – Soft). Pirelli makes that decision depending on how abrasive and destructive for tyres is the particular track. For each racing weekend in 2021 teams receive 8 red (Soft) sets of tyres, 3 yellow (Medium) and 2 white (Hard) sets for each card and are free to use them as they wish, but they need to use at least two compounds in the race. This rule is not enforced if there are wet conditions. For those occasion the team receives 4 sets of Intermediate and 3 sets of Full Wet tyres for each car.
Generally softer tyres have better grip (and hence cars can go through corners at higher sped → lower lap times), but lower durability and hard tyres have good durability but worse grip. They also have different operating temperatures, so it’s easier to overheat the soft tyres and more difficult to put the hard tyres into good operating temperatures. Harder tyres usually provide slower lap times, but you can cover longer distance in the race. It’s a balancing act – you can use three sets of softer tyres and hope that with better lap times you can cover the 20-30 seconds time you needed for additional tyre change. Or do only one stop on slower/harder compounds. This usually works better on tracks where it’s harder to overtake – even if you’re slower because of the harder compound, the faster car may not be able to overtake you. We could talk about it for hours, but I’ll introduce more nuances as we go along. This is enough nerd talk about rubber for now.
ML.NET
I’m going to use ML.NET in this series of posts. I have some experience with it, but I want to learn more about the whole ecosystem while doing some fun project. Training, inference, deploying models, visualizing data – basically making a working “product” and seeing what tools we can use along the way. For context, I generally have experience building machine learning – powered products in Python frameworks, and I also have years of knowledge working in .NET projects. I want to connect those worlds. And even though I have some previous knowledge, I’m going to try to jump into it like I know nothing and make it a learning experience for you and me.
ML.NET is an open-source cross-platform machine learning library built on .Net. It implements several type of ML algorithms for solving few most common problems. It doesn’t have the flexibility of TensorFlow, but the learning curve is much more approachable, and it allows you to be fairly productive pretty quickly without investing a lot of maths knowledge. Is it the responsible approach? Probably not in all cases. You should always have a good understanding of tools you use to not hurt yourself or others.
We’re solving a regression problem
ML.NET approach is: start first with what kind of problem you’re solving. When trying to predict a specific numeric values (number of laps that tyre will be used), based on past observed data (tyre stint information from previous races), in machine learning this type of prediction method is called regression.
Linear regression is a type of regression, where we try to match a linear function to our dataset and use that function to predict new values based on input data. A classic example of linear regression is predicting prices of a flat based on its area. It’s a fairly logical approach – the bigger the flat the more it costs.
Example of linear regression.
So on the image above you can see a simple chart with input data (green dots), the linear function that we matched to the data. And the red dot is our prediction for a new data point. Matching that function to the data set is the “learning” part, sometimes also called “fitting”. Predicting new value from that function is “inference”.
The input values are called “features”, and the outputs we have in our learning data sets are called “labels”. With one feature we can visualize that data in two dimensions, but the more features the visualizations gets a bit out of control of our 3-dimensional minds. Fortunately maths much more flexible. Initially I’ll be using 11 features for our dataset to solve this problem.
My dataset
So where do I get the data? I’m using what’s publicly available, and hence my results will be much less precise than what teams can do. But let’s see where that will lead us.
I decided, as a first task, to predict a “stint” length for each driver on each type of tyre. Stint is basically a number of laps driver did on a single set of tires. If we have one change of tyres in the race, we have two stints – one from the start to the tyre change, and the second from the tyre change to the race finish. Two tyre changes – three stints. You get the grips of it. Sometimes a stint is finished with less positive outcome, like accident, or retirement because of technical issues. Sometimes it extends too much and finish with a tyre puncture. Usually teams will try to get max out of the tyres, but not overdo it.
I took data from charts like this and then watched race highlights or in some cases full races to figure out why some stints were shorter than expected. On the image below from this year’s Bahrain GP you can see that most drivers were doing 3 stints, or to use Formula1 lingo – they were on “two stop strategy”. And for some drivers the lines are shorter, because their races finished with one of those less-favourable outcomes.
Tyre stints for each driver in 2021 Bahrain Grand Prix. Source: F1TV.com
To make reasonable predictions, I focus only the period from 2017 to 2020. Why this period? 2017 was the last time we had major changes in aerodynamics and tyre constructions. And even though there were some minor modifications since then, the cars are in principle similar, and they abuse the tyres similarly. We also have many drivers overlapping, so we can find some consistency in their style of driving.
I also picked only races on the same track for this first approach. There are few reasons. I’m removing the variable of different track surfaces. The races are the same length in this period, so I can focus on predicting stint lent in “laps” and don’t need to worry about calculating it from distance covered.
Each row in the dataset is one stint. I collected features as listed below:
Date – mostly for accounting reasons, but maybe in future we could extract time of year for some purpose.
Track – different track, different surface properties impact tyre wear (although for now it’s only Bahrain)
Layout – sometimes racing uses different layout on the same track (for example Bahrain has 6 layouts, out of them 3 were used in Formula 1 since 2004, but mostly irrelevant for the 2017-2020)
Track length – will be useful when predicting covered distance instead of laps for future races
Team – different teams approach strategy a bit differently (for example priority for different drivers) – may be relevant in future
Car – different cars have different aero properties and “eat-up” tyres differently
Drivers – different driving styles, different levels of tyre abuse – for example Lewis Hamilton owes several of his victories to great tyre management
Tyre Compound – which tyre compounds were used during that sting. I use the C1-C5 nomenclature as on different races “Soft” can mean different things, and C1-C5 range is universal (apart from year 2017, but I mapped it to current convention)
Track Temperature – warmer surface allows quicker activation of tyres, but also quicker wear; too cold is not good either, because tyres can be susceptible to graining, which also lowers their lifespan.
Air Temperature – not sure, but I had access to data, so decided to keep it
Reason – why the stint ended – for example Just regular Pit-stop, End of Race, Red Flag, Accident, DNF
Number of laps covered in a stint – this will be my “label”, so what we’re training to be able to predict
The code
The code, minus the dataset, is available on my GitHub.
As I mentioned, my approach will be like I’m completely new to ML.NET. We already established that we’re solving a regression problem. So I copied the sample regression project that predicts rental bikes demand and made minimal changes to the code.
First, I have a single dataset. In machine learning you generally want to have a training set – to train, and a testing set to test your hypothesis on data. Testing data shouldn’t be process by algorithm. It’s a bit like taking a test knowing sample questions, but not having the exact question that will be on the test. Bike rental example has already those datasets divided, but I had to add that bit in my case.
// Load data var data = mlContext.Data.LoadFromTextFile<TyreStint>(DatasetsLocation, ';', true); // Divide dataset into training and testing data var split = mlContext.Data.TrainTestSplit(data, testFraction: 0.1); var trainingData = split.TrainSet; var testingData = split.TestSet;
Next I build the calculation pipeline. It’s basically the order of transformation we want to do on the data. I just replaced field names from the example code with the fields I use in my dataset. You can notice quite a lot of “OneHotEncoding”. This is an operation that indicates this field is a categorical data. So for example, we don’t want to assume that “Alfa Romeo” is better than “Red Bull” because it sits higher in alphabetical order. We also normalize the values for Numerical data, so they’re easier computationally for the fitting algorithm.
So far so good, let’s now train that pipeline with our test data. It looks surprisingly simple. I didn’t mess with the algorithm or the parameters of it. Just took the same regression algorithm used in Bike Rental examples. There will be time for some optimizations later.
var trainer = mlContext.Regression.Trainers.Sdca(labelColumnName: "Label", featureColumnName: "Features"); var trainingPipeline = pipeline.Append(trainer); // Training the model var trainedModel = trainingPipeline.Fit(trainingData);
So is our model good to make some predictions? Let’s try it out:
var predictionEngine = mlContext.Model.CreatePredictionEngine<TyreStint, TyreStintPrediction>(trainedModel); var lh1 = new TyreStint() { Team = "Mercedes", Car = "W12", Driver = "Lewis Hamilton", Compound = "C3", AirTemperature = 20.5f, TrackTemperature = 28.3f, Reason = "Pit Stop"}; var lh1_pred = predictionEngine.Predict(lh1); var mv1 = new TyreStint() { Team = "Red Bull", Car = "RB16B", Driver = "Max Verstappen", Compound = "C3", AirTemperature = 20.5f, TrackTemperature = 28.3f, Reason = "Pit Stop" }; var mv1_pred = predictionEngine.Predict(mv1);
I run two example runs for top drivers. Lewis Hamilton got 19.46 laps on C3 tyre (“Medium” for Bahrain) and Max Verstappen – 14.96 lap. First of all values are reasonable – they’re not outrageously low or high. They also show what’s generally tends to be true – that Lewis Hamilton is better at tyre management than Max Verstappen. But they most likely include the fact, that Max was doing very poorly in recent years in Bahrain and on average had shorter stints because of DNFs.
So how good did we do?
So here are our predictions vs real stints of drivers. If the drivers took more than one stint on the compound, I listed all of them. If the driver didn’t use that tyre, the Actual column will be empty.
Driver
Compound
Prediction
Actual
Lewis Hamilton
C2
26,78
15; 28
Lewis Hamilton
C3
19,81
13
Lewis Hamilton
C4
16,18
–
Valtteri Bottas
C2
28,53
14; 24
Valtteri Bottas
C3
21,56
16; 2
Valtteri Bottas
C4
17,92
–
Max Verstappen
C2
22,27
17
Max Verstappen
C3
15,31
17; 22
Max Verstappen
C4
11,67
–
Sergio Pérez
C2
26,37
19
Sergio Pérez
C3
19,41
2; 17; 18
Sergio Pérez
C4
15,77
–
Lando Norris
C2
25,62
23
Lando Norris
C3
18,65
21
Lando Norris
C4
15,01
12
Daniel Ricciardo
C2
29,19
24
Daniel Ricciardo
C3
22,22
19
Daniel Ricciardo
C4
18,58
13
Lance Stroll
C2
23,35
28
Lance Stroll
C3
16,39
16
Lance Stroll
C4
12,75
12
Sebastian Vettel
C2
23,15
31
Sebastian Vettel
C3
16,18
24
Sebastian Vettel
C4
12,54
–
Fernando Alonso
C2
32,52
3
Fernando Alonso
C3
25,55
18
Fernando Alonso
C4
21,91
11
Esteban Ocon
C2
32,11
24
Esteban Ocon
C3
25,14
18
Esteban Ocon
C4
21,50
13
Charles Leclerc
C2
29,28
24
Charles Leclerc
C3
22,31
20
Charles Leclerc
C4
18,67
12
Carlos Sainz
C2
26,97
19
Carlos Sainz
C3
20,01
22
Carlos Sainz
C4
16,37
15
Pierre Gasly
C2
32,93
15; 13
Pierre Gasly
C3
25,96
4; 20
Pierre Gasly
C4
22,32
–
Yuki Tsunoda
C2
30,88
18; 23
Yuki Tsunoda
C3
23,91
15
Yuki Tsunoda
C4
20,27
–
Antonio Giovinazzi
C2
26,41
18
Antonio Giovinazzi
C3
19,44
12; 25
Antonio Giovinazzi
C4
15,806
–
Kimi Räikkönen
C2
25,65
16
Kimi Räikkönen
C3
18,68
13; 27
Kimi Räikkönen
C4
15,04
–
Nikita Mazepin
C2
25,92
–
Nikita Mazepin
C3
18,95
–
Nikita Mazepin
C4
15,31
–
Mick Schumacher
C2
25,92
22
Mick Schumacher
C3
18,95
14; 19
Mick Schumacher
C4
15,31
–
George Russell
C2
21,46
–
George Russell
C3
14,49
23; 19
George Russell
C4
10,85
13
Nicholas Latifi
C2
22,00
–
Nicholas Latifi
C3
15,04
18; 19
Nicholas Latifi
C4
11,40
14
So predictions are actually relatively reasonable. Those are not numbers that do not make sense. The model figured out that the C2 (Hard) tyres are lasting longer than C3 (Medium) and C4 (Soft). The numbers seem to be higher for drivers with better tyre management skills. They of course do not match the real numbers from the race, because there’s a lot of other things happening in the race. Crashes, retirements, reacting to strategy of other teams. Those are all things that we’ll need to somehow include in the future, but that’s not a problem for today. Overall I feel good about it. I think we have a decent model.
What does the metrics say?
But do we? Running some metrics that ML.NET have built in…
I’m not going to dig into what all of those metrics mean and just focus on the R2 Score, also known as Coefficient of determination. The better our function fits the testing data, the closer that value is to 1. 0 is bad. Negative is catastrophically bad. So even though some of our values looks reasonable, it’s probably accidental at this point. We’ll explore possible reasons for that and other metrics in future posts. Tyres vs Michał 1:0.
What’s next?
In the next instalment we’ll look at two races of Imola and Portimão. They will be tricky to get any reasonable results, because both of them will be running for the second time in recent years. But this will be a good occasion to extend our model and dataset to include other tracks. We’ll no longer be using laps as our label, because different tracks have different lengths. We’ll use total distance covered and calculate the number of laps out of it.
We should also look into removing some irrelevant data, like stints ended with crashes or done purely to beat the fastest lap (it’s a thing, but a long story to explain).
At some point we’ll also have to take a crack and why those metrics are so bad, and try different regression optimizers and different hyperparameters.
Yesterday I passed the AZ-900 exam for “The Azure Fundamentals” certification. This is the most basic Azure certification and is suggested as the first step to more serious certificates in that area.
But why?
I worked with Azure last two years. Why would I pass the most basic certification? Currently, I’m working together with my colleague Marcus Mazur on the development paths for the developers in our company as a part of our knowledge package. Times, when tretton37 has been a purely .NET shop, are long gone, but Azure and Microsoft stack are still an important part of our offering. I’m not really a “certificate believer”, but our customers are. They either believe they represent skills or have contractual or legal obligations to use consultants with skills confirmed by certificates. And so we encourage our developers to obtain certificates and we help in that process. And since I’m the one planning the paths for the people, I also want to test them on myself.
Why is this a good first certificate?
It’s a relatively low body of knowledge and easy to pass, but you get familiar with the process. Currently, due to Covid-19, the exams are done online and it’s a bit different experience. The check-in process went ok, but the actual exam tool has some issues and it adds to the stress of the whole experience. So starting with the relatively non-important and easy exam is a good way to get familiar with the process. In future, I’ll know that the exam tool has some problems and I will be more emotionally prepared for that, so I can focus on the harder exam.
How, if you’re new to Azure?
Many people will approach this as a newbies in the Azure/Microsoft world. I highly suggest going through this official Microsoft learning path:
And also watch this 3hrs video from freeCodeCamp that goes through all the topics necessary to pass the exam:
Now – they may or may not be sample questions available on the internet. They may or may not be similar to the ones on the actual exam. If I were you, I’d look at them ;)
How, if you’re Azure veteran(ish)?
I approached this exam with around 2 years experience of running software projects on Azure. In that time I used a decent amount of available services, but not all of them. So most of the questions that asked if service X is good for Y were relatively easy for me. But I’d still suggest looking at those potentially-probably-close-to-real sample tests because there’s a bunch of tricky questions about how you can do operation X on Azure using Google Chrome laptop or if SLA for service Z is 99.99% or 99.95%. You know, things you’ll never need nor care about when using Azure, but apparently they’re important.
What’s next
I’ll be passing a few more Azure exams in the near future. Let me know if posts like that are interesting for you.
The first programming conference I fell in love was DevDay. It really opened my eyes when I went there for the first time in 2012 and it never failed to satisfy – I wrote about it multiple times. DevDay won’t be organized this year, or maybe even won’t be organized, period. But don’t worry – Michał and Rafał (together with other awesome people) are starting a new conference. I invite you to DevConf!
I sent two talks for the CFP and both have been accepted. So I’m super happy, and also a bit stressed – this is going to be the first time I’m doing two talks at the same conference. Both new. Challenge accepted!
The first talk will be related to my growing in recent years interested in Machine Learning. I’ll try to explain basics of the technicalities of training and evaluating ML models in approachable ways. You’re probably gonna be disappointed how easy it is to get a relatively good working model. I hope to get you interested enough, that you won’t surrender when the first obstacles show up.
The second talk will be about my other fascination. How computers actually work? I’ll start with what most programmers know the best these days – one of the high-level programming languages. From there I’ll explore what lays beneath, what layers built up over last few decades. We’re standing on arms of the giants of the past and it’s a good thing to appreciate it.
DevConf is held on 13-15th September in Kraków, Poland. It’s less than a 2hrs flight from most places in Europe. One day of workshop and two days of three tracks talks for very affordable price. Make sure you stay for the weekend – traditionally we have a lot of fun there also after the conference. Register here! Hope to see you there!
As mentioned in my last week Elixir blog post, I produced some quick fake API based on Azure Functions. I thought it’s gonna take a couple of minutes, but it turned out to be a whole adventure in itself.
The creating of a function is a breeze.
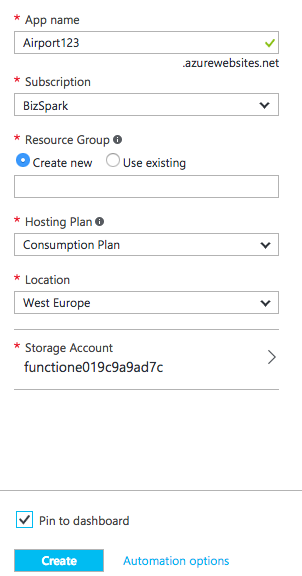
Go to Portal, click big green “+” sign and search for “Function App”
Pick Function App published by Microsoft
Fill all the necessary fields like App name (must be globally unique) or location. For hosting plan I used “Consumption plan” which means, I pay only for the time that function is running. I also like to pin my stuff to the dashboard, so it’s easier to find.
It will take several minutes to deploy.
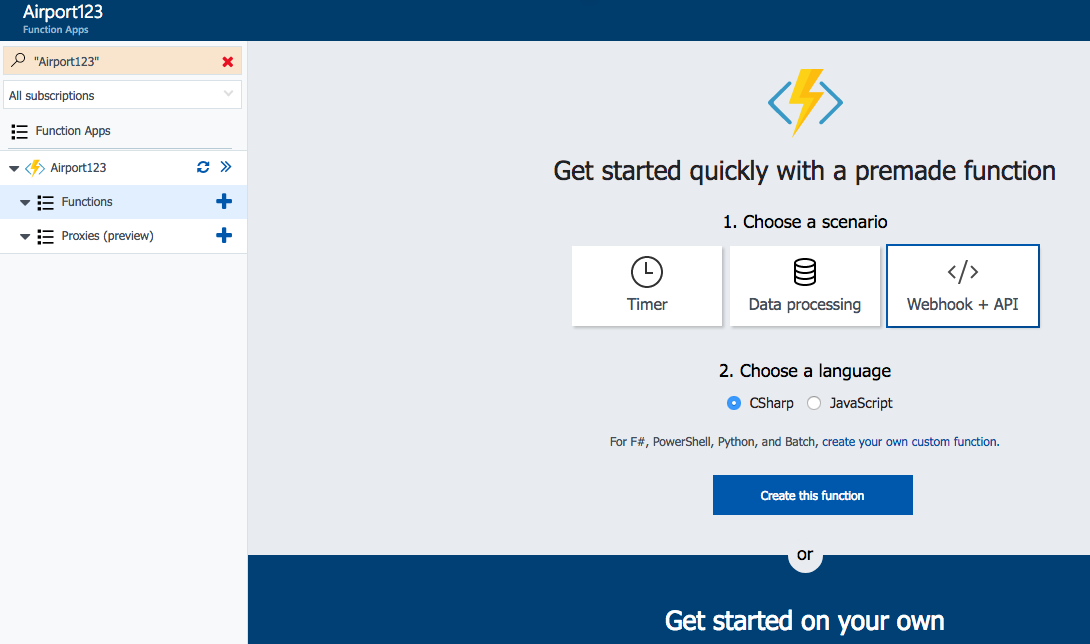
Now you can create your functions for the app. F# is hidden in small print just above “Create this function” button. So click “create your own custom function”.
Then with Language drop-down, pick “F#” and for Scenario – “API & Webhooks”. There should be on the F# function triggered by HTTP request. That’s the one you want for API.
You’ll get premade piece of code with a simple function that is triggered by HTTP POST with name object and responses “Hello “.
Then I started writing the logic I wanted. I made an array of hard coded airport data. I made the function to accept only GET requests (you can change it in function.json file). In code, I parse query strings and get the airport IATA code. If I have this airport in my array, I response 200 with JSON containing the data. Otherwise, I return 404. If there’s no parameter in the query string, function answers with 500.
It’s relatively simple and straightforward F# code. I just struggled a lot with debugging. The small editor on Azure doesn’t give you static analysis, nor type information and no squigglies. You need to run the function and check for compilation errors or runtime errors. There was also some weird scoping behaviour, that forced me to declare the Airports array within the function. Anyways, after 2hrs I had an API that did what I wanted. You can see the code below. It’s not bulletproof, but it does the job. And I got to play with Azure Functions a bit.
If you want to read more about other types of F# Azure Functions, Mathias Brandewinder wrote recently two posts about timer and queue triggered functions.
That’s all for today. Tune in next week for another part. Also, check previous episodes. And if you’re interested in machine learning, look into my weekly link drop.
I was planning to start furiously coding on my project for this second post and start building some web API with Phoenix. But Gutek suggested, that first I should really dig into some internals that will help me understand how Phoenix works – thanks for this advice. On top of that, I didn’t really have time to dig properly, but I managed to look a bit into syntax and I have mixed feelings.
I won’t be doing an introduction to Elixir post here. You can find a lot of resources on that, for example, Gutek’s series in Polish, official documentation or this short article. Instead, I’m gonna compare it to something that I’m familiar with – F# syntax. And it’s nowhere near comprehensive comparison. Just a few things that I found interesting and worth noting.
Comparing stuff
Right from the start, there are few differences here. F# uses just ‘=’
to compare if two things are equal. Elixir has two comparison operators ‘==’ and ‘===’. First one is standard compare operator. Second, from my current understanding, is useful mostly for comparing if numbers are of the same type. To explain, look at this example:
Although we didn’t declare any types in F#, it will infer them during compilation. And as a strongly typed language, will not allow comparing values of two different types.
Elixir is dynamically typed. It means, that it will also infer types, but this will happen in the runtime and also will do casts for you.
For not-equal F# uses ‘<>’ and Elixir ‘!=’ and ‘!==’. Generally, Elixir is here more consistent with most programming languages, so I’ll give it a point here, but I appreciate type safety of F# also. You can also notice that those languages use a different convention for comments.
In Elixir ‘=’ is also used for matching which is quite powerful.
Immutability
Although both languages are immutable by default, there are some differences in approach.
In Elixir, value is immutable so you cannot change it, but you can assign the “label” to some other value.
# Elixir
a = 1 # value "1" is now labelled "a"
a = a+1 # label "a" is changed: now "2" is labelled "a"
a = a*5 # value "10" is now labelled "a"
But if you want to refer to the current value of, i.e. when using match operator, you can do it this way:
# Elixir
b = 1
b = 2 # rebinding variable to 2
^b = 3 # matching: 2 = 3 -> error
First thing that came to my mind when saw it, were C language pointers :)
F# allows mutability, but it has to be openly declared, and then you need a different operator to change the value. Mutability is mostly allowed for compatibility reasons with .NET libraries, so you shouldn’t abuse it.
// F#
let a = 1 // binding value "1"" to label "a"
a = 2 // returns false (it is just comparing)
a <- 2 // compile error
let mutable b = 1 // binding value "1"" to mutable variable "b""
b <- 2 // changing value of variable "b""
b = 2 // returns true
In this part, F# is for me clear winner. You cannot change value bind to a label. It is much less confusing and makes more readable code.
List operations
List operations are generally very similar. What I found interesting in Elixir, you can match not only head and tail, like in F# but several first elements: EDIT: As anonguy pointed out in the comments, that’s also possible in F#. Updated the code sample.
# Elixir
[ a, b, c | tail ]
// F#
head::tail
a::b::c::tail // that also works
There are two things worth mentioning while we’re on lists. Pipe operator (|>) works pretty much the same in both languages. In Elixir it binds the first parameter of the function, and in F# last one, but that’s the main difference. It’s a matter of convention and doesn’t really matter in the end. Just worth knowing. EDIT: as Chris and Paul Blair pointed out, this has a tremendous impact on how currying and partial application works and makes F# much easier in that regard. Check out the comments for details.
The classic approach to lists is that you usually iterate through them with for loop. It’s possible in F#, but Elixir doesn’t have “for” loop. You have to do it in a more functional way, i.e. through recursion. For me, that’s a huge plus on Elixir side, because it forces you to use proper functional approach. In F# for loops are a gateway drug to imperative programming :).
Functions and modules
The first thing that I find annoying in Elixir is that every ‘def’ and ‘defp’ must be paired with ‘end’. It’s like curly braces all over again. Or Visual Basic. It makes code dirty and is excessive. In F#, blocks of code are delimited by the level of whitespace, similar to Python.
In Elixir, functions must be wrapped in Modules. It doesn’t create a big pain, but again – something I don’t have to do in F#. On the other hand, Elixir allows you to do multilevel Modules, which may be convenient in some situations. EDIT:Anil Mujagic mentioned in the comments, that it also works in F#.
Pattern matching
A bit about Elixir pattern matching was mentioned in the first paragraph. “=” parameter has some impressive qualities. You can also pattern match on function parameters, like shown below in the second example. And you can further simplify it with guards.
# Elixir
# case statement
def blank?(value) do
case value do
nil -> true
false -> true
"" -> true
_other -> false
end
end
# pattern matching on function parameters
def blank?(nil), do: true
def blank?(false), do: true
def blank?(""), do: true
def blank?(_other), do: false
# pattern matching on function parameters with guards
def blank?(value) when value in [nil, false, ""], do: true
def blank?(_other), do: false
In F# it looks similar to the case statement in Elixir. You can also use guards with it and much more.
// F#
let x =
match 1 with
| 1 -> "a"
| 2 -> "b"
| _ -> "z"
I couldn’t recreate the same example easily, because of strong typing of F#. The Same variable cannot have values of different types, and nulls are non-existent in this language. You could have something similar using discriminated unions.
I’m not a fan of Elixir’s approach to this problem with declaring several functions. I prefer F# way again.
Summary
As mentioned in the beginning, I have mixed feelings. For the last couple of years, I’ve been hearing a lot how beautiful Elixir is. And I can imagine for a lot of folks coming from other languages it is. But I’ve been spoiled with F# for last 5 years and I must admit, it’s still my number one. That being said, Elixir lands on the strong second position in terms of beauty. I do appreciate some big uncompromising design decisions that José made to make Elixir much more functional. F# has some “gateway drugs” to imperative programming, as they wanted to leave that option open too and be compatible with the rest of .NET. Big points for Elixir for that. There are some features of F# like discriminated unions or units of measures, that I haven’t found a good replacement in Elixir, but I’m also at the beginning of my journey. I also like F# more for strong typing.
Additional resources
F# has an abundance of operators. Some of them are really crazy. Check this Microsoft document to see all of them.
Quick guides on Elixir and F# syntax. The second one comes from the excellent blog of Scott Wlaschin. If you want to dive into F# more, I highly recommend it.
Next week I’ll be diving into internals. Hopefully, I will find time for that. Come back next week for more Elixir, and if you’re interested in Machine Learning, check my subjective drop of interesting articles in that area.
This post was edited to fix inaccuracies that were pointed out in the comments. Thank you for kind, constructive and informative comments!
In last month or so I did three talks on F# in Poland. I can see gaining interests and there’re already other people speaking about F# in Polish community. This is awesome!
Kraków, 25th September
A Day before DevDayKGD.NET organized meetup with two talks. This was great opportunity for my employer tretton37 to get some more street cred in Poland, so we decided to sponsor some food and drinks. There were two speakers – me and Maciej Aniserowicz, who’s kind of a rock star of Polish .NET community (BTW, check out his new podcast (in Polish)). I did my already well known introduction talk to F#. I had quite a big audience (around 100 people) and they were very engaged. I enjoyed great question and feedback I got after the talk. Looks like it’s very active .NET group. I used the same slides and code as in Warsaw couple months before.
Next dey was a DevDay :). I’m big fan of this conference and it delivered again. There were a lot of semi-negative opinions on the Internet afterwards, which is very sad and unfair. Looks like DevDay became victim of its own success. Last year was fuckin awesome, and people had some overgrown expectations. The truth is, it was fuckin awesome again this time and I can’t wait for next year’s edition. Videos are already online and you can watch them on youtube. But the strongest point of DevDay for me is community impact. It made largely distributed Polish .NET scene more united. People are visiting each other’s group and exchange experiences and knowledge. Programmers from all around Poland know each other better and lot’s of credit for that goes to Michał and Rafał.
Interwebz, 18th October
On Saturday evening I did a talk on Polish virtual conference dotnetconf.pl. From statistics I could see there were about 70 people watching it live. It’s a little bit weird to talk to computer without seeing your audience. I’m not happy how this talk went, but you can judge by yourself, because it’s been recorded (Polish). Feedback I got afterwards kind of matched my expectations – 24 positive, 16 neutral and 2 negative opinions. Again – same slides and code as in Warsaw.
This was the second edition of dotnetconfpl, great initiative by Michał, Paweł and Jakub. It’s Saturday afternoon full of code. Made by Polish developers for Polish developers. And because it was virtual, I could do talk from my desk in Sweden. I also very enjoyed discussions that went on whole day on dedicated jabbr channel.
Poznan, 30th October, PolyConf
Few days ago I did completely new talk. This time about cross-platform mobile development with F# and Xamarin. So this was new talk, and also my first talk in English, and biggest audience so far. Lot’s of new experiences. I was quite nervous before, but seems like everything went well. I’ll see video in a couple of days to make sure, but right now I feel it was my best talk so far.
The conference itself is evolution of well known RuPY. This time they widen topics to other programmic languages, so you could witness talks on JavaScript, Haskell, Erlang or F#. Pretty cool experience, and lot’s of inspiration how to move concept from other technologies to my daily job. The conference, even though it was hosted in Poland, gathered mostly international crowd. I’m putting it on my calendar for next year, because really enjoyed it.
What’s really cool and makes me happy, there’re other people who start talking about F# in Polish community. Few weeks ago my friend Kuba Walinski asked me if he can reference my talk, as he’s gonna do his own about F#. Hell yeah, you can. It’s great that we’re spreading F# love :). He spoke at Developer Days in Wrocław and you can read his thoughts about it on his blog.
There’re some other F# events coming up in Poland, so I’m thinking about starting some kind of Polish Monthly F# news, similar to Sergey’s weekly news, but focusing on our local community. Stay tuned :).